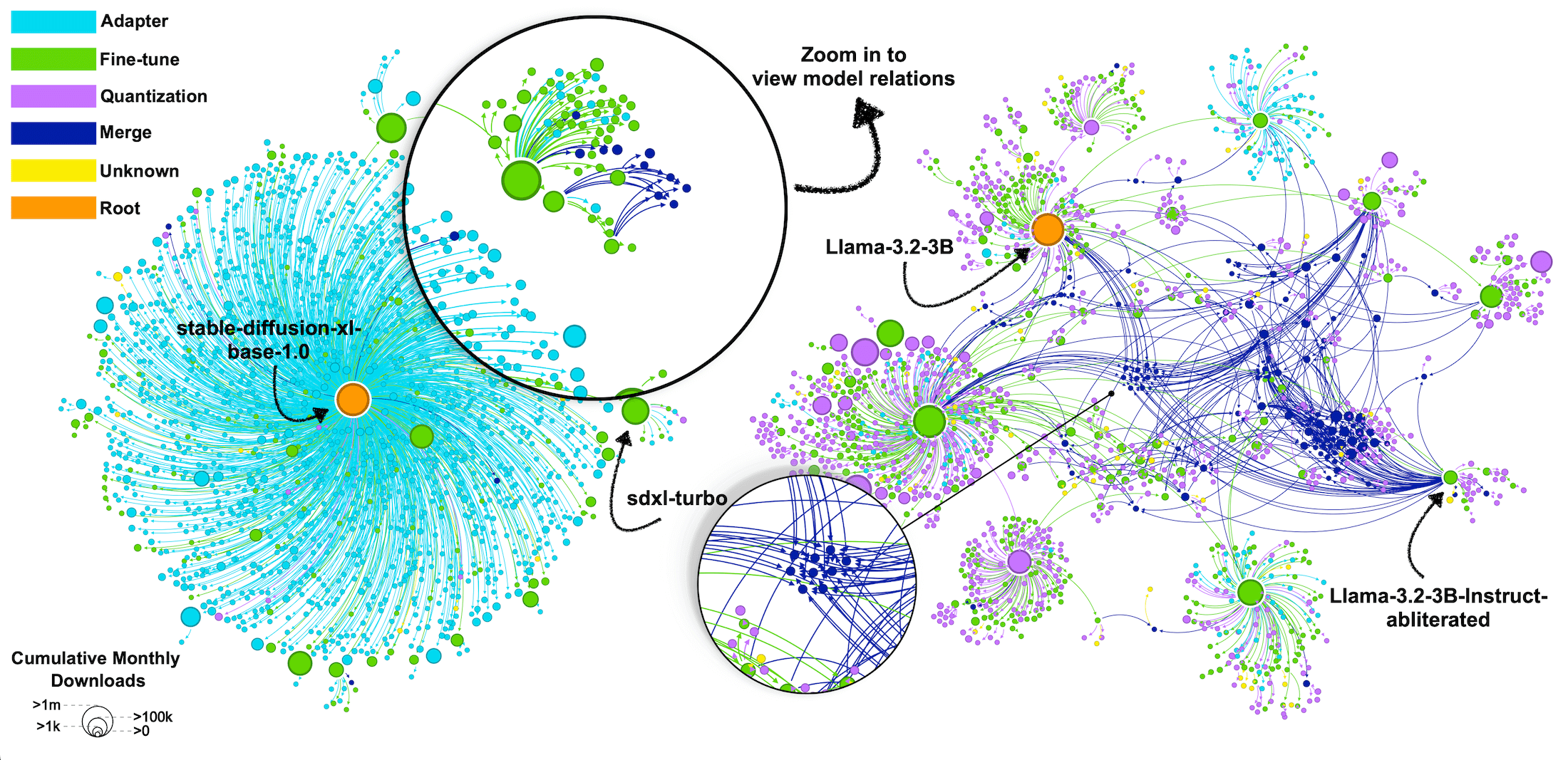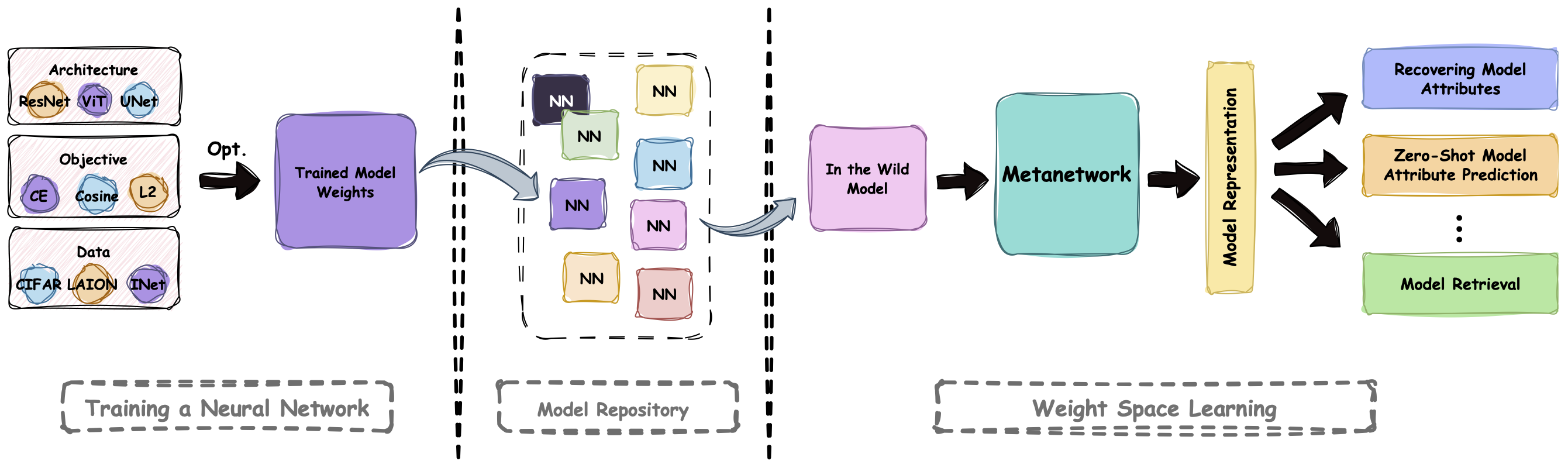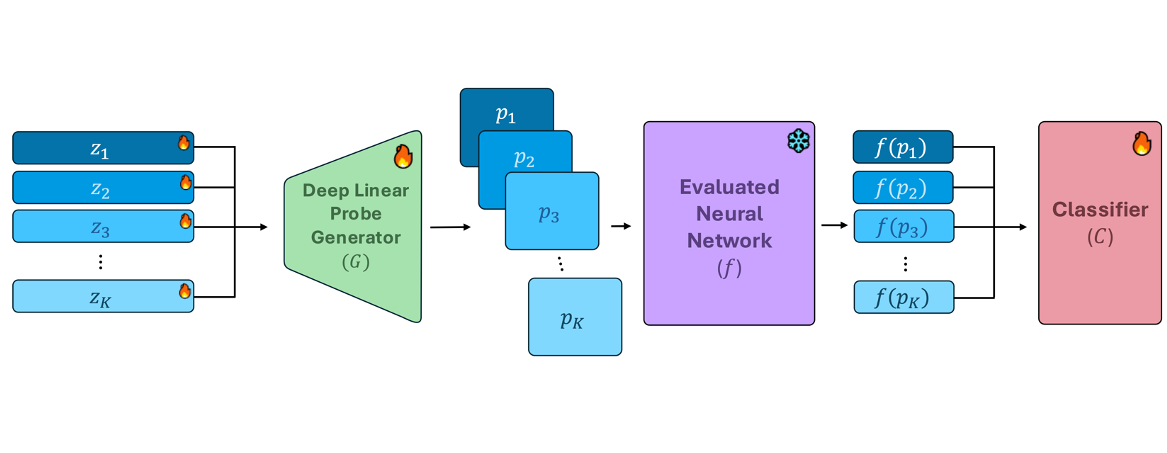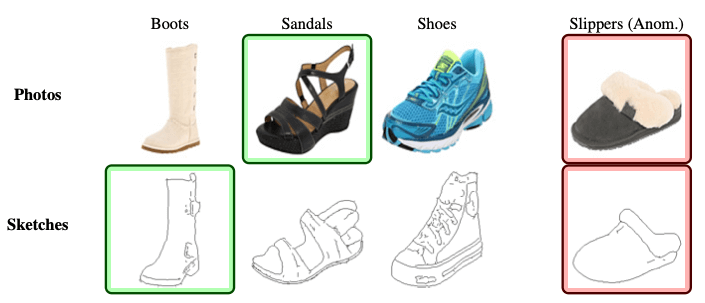
Can this Model Also Recognize Dogs? Zero-Shot Model Search from Weights
Arxiv Preprint
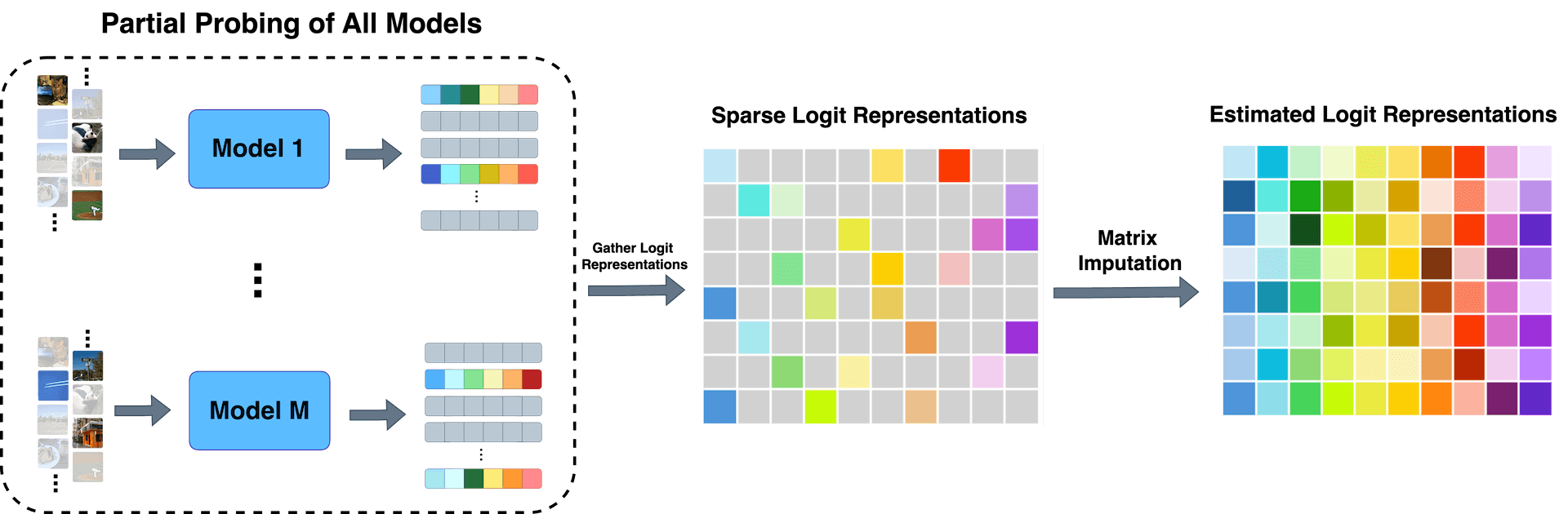
We propose ProbeLog, a method for searching models in large model repositories. ProbeLog embeds each logit of classifier models separately and matches that representation with a text prompt. This allows users to search for models that can recognize a target concept, such as "Dog" without access to the model metadata or training data.