Phonetic Features Injection
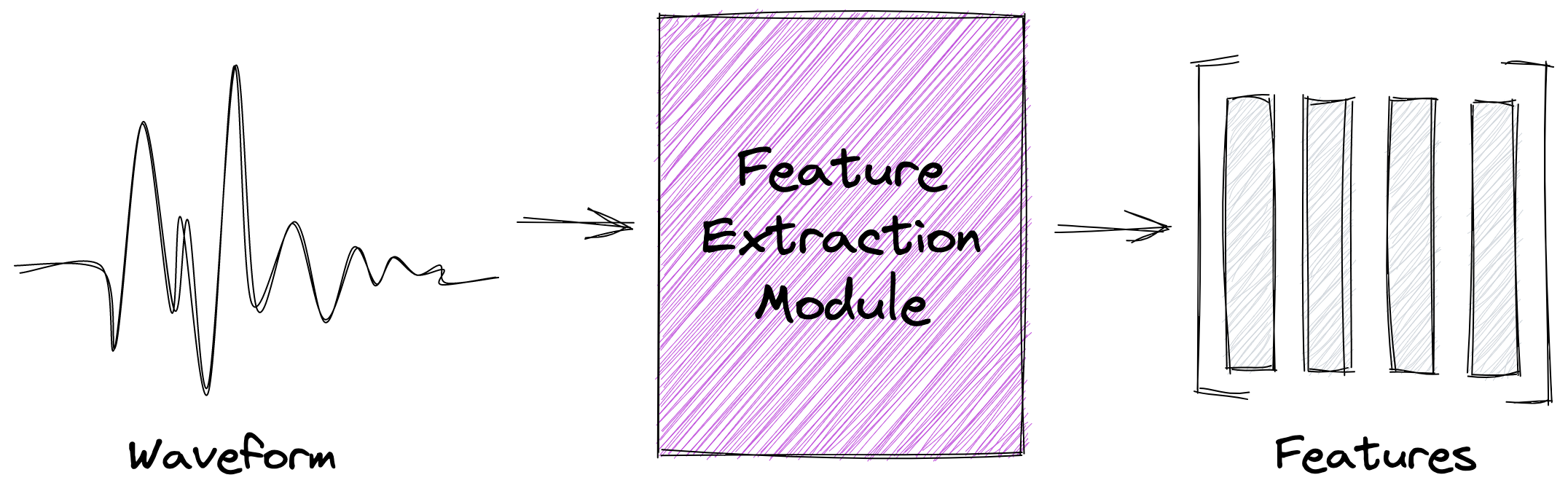
Consider a phonetic feature vector as an embedded representation of a speech signal which captures its
content and intents.
One may then conclude that using some of the information held within this representation
could benefit speech enhancement as it shares prior information regarding the content of the signal.
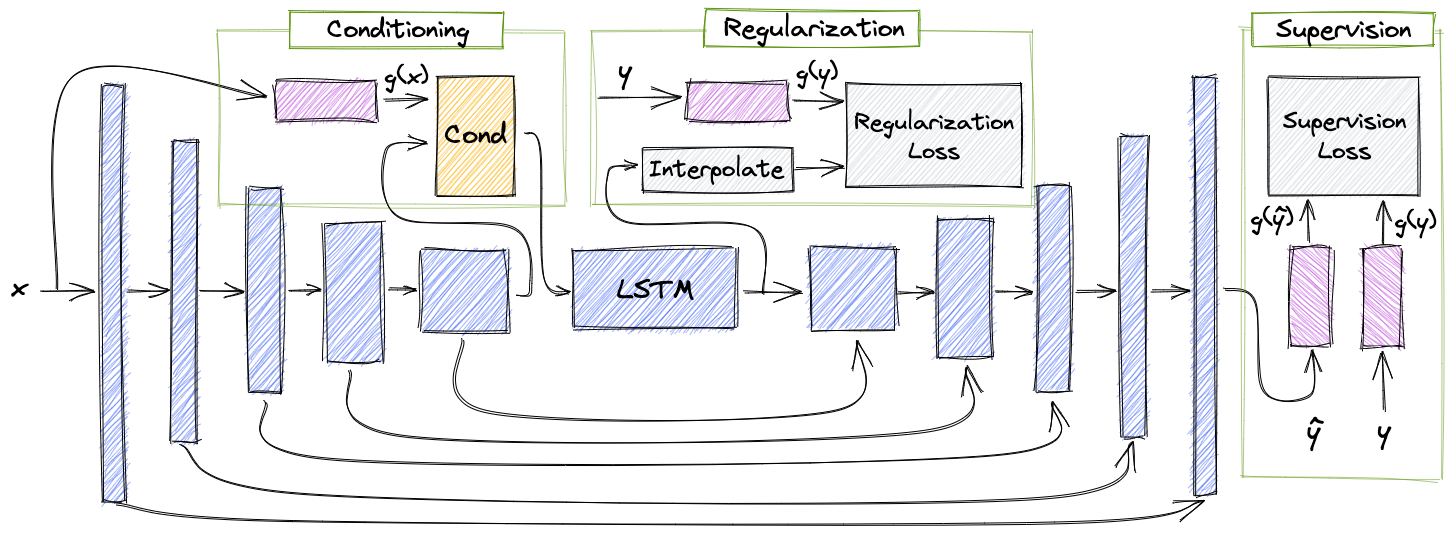
In this work, we explore three modeling settings to inject phonetic information into a speech enhancement
model, namely Regularization, Supervision, and Conditioning.
Regularization
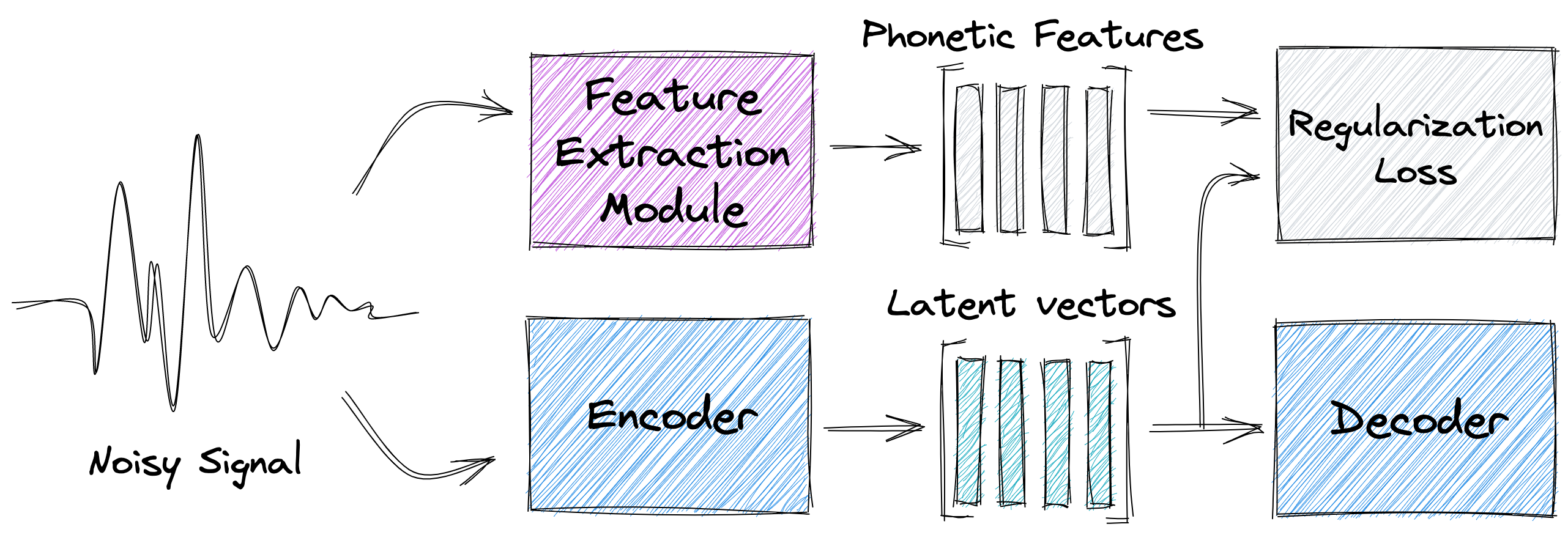
Under this setting we encourage a latent representation, sampled at a predetermined location, to encode some of the information held within the extracted phonetic features.
We do this by imposing a regularization loss between the latent representations and the extracted phonetic features.
Intuitively, this could benefit the model during inference time as it receives gradients from qualities perceived by the phonetic features as well its main objective throughout the training stage.
Supervision
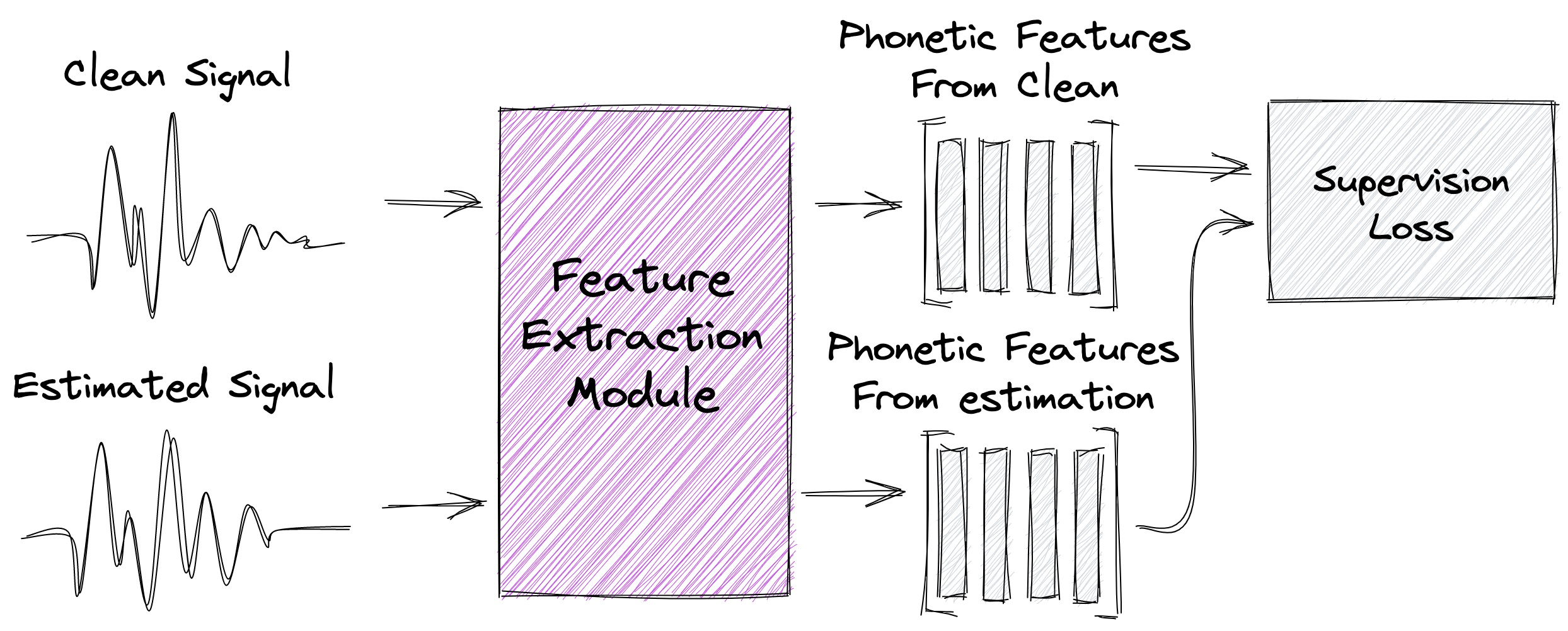
Under this setting we take advantage of the qualities encoded by the phonetic model, to capture perceptual differences between the encoded features drawn from the clean ground truth signal to the ones obtained from the model’s estimated signal.
We draw gradients from the difference by integrating a supervision loss as additive term to the main training objective.
Conditioning
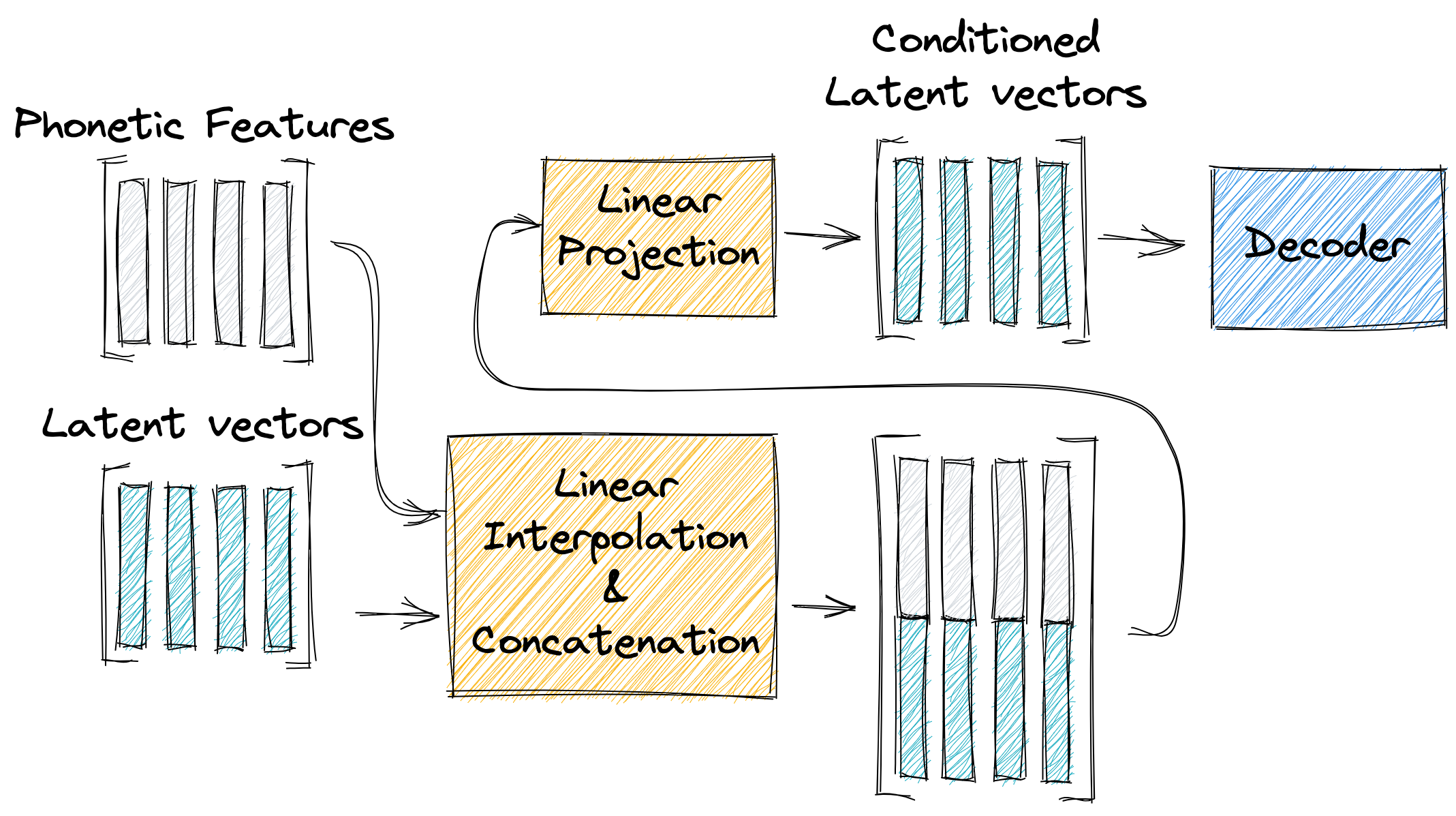
The last among the suggested techniques is conditioning
Under this section, opposed to previous ones, we incorporate phonetic features into the model’s forward pass, meaning that the conditioning occurs during inference time as well.
We purpose a basic module to perform the phonetic features conditioning which consists of a linear interpolation and concatenation followed by a simple linear projection layer to obtain the same expected model dimensions.
By doing so, we allow the model to benefit directly from pretrained encoded representations, and to learn complementary features encoding throughout training
Illustration of all methods