HEBDB
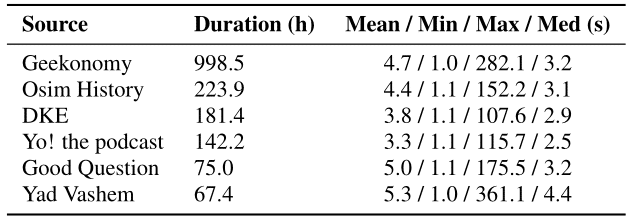
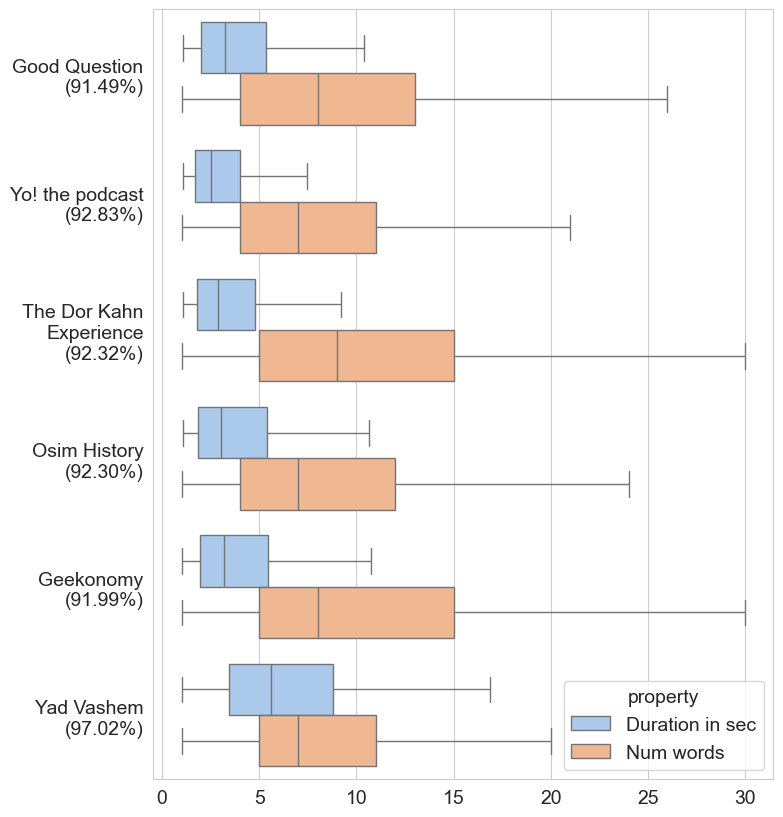
HEBDB contains natural dialogues of spontaneous speech. It is comprised of both testimonies
from World War II survivors and five podcasts covering a wide range of subjects and
speakers. While the testimonies provide firsthand accounts of historical events, the
majority of our dataset consists of podcasts covering diverse topics such as economy,
politics, sports, culture, science, history, and music, to name a few.
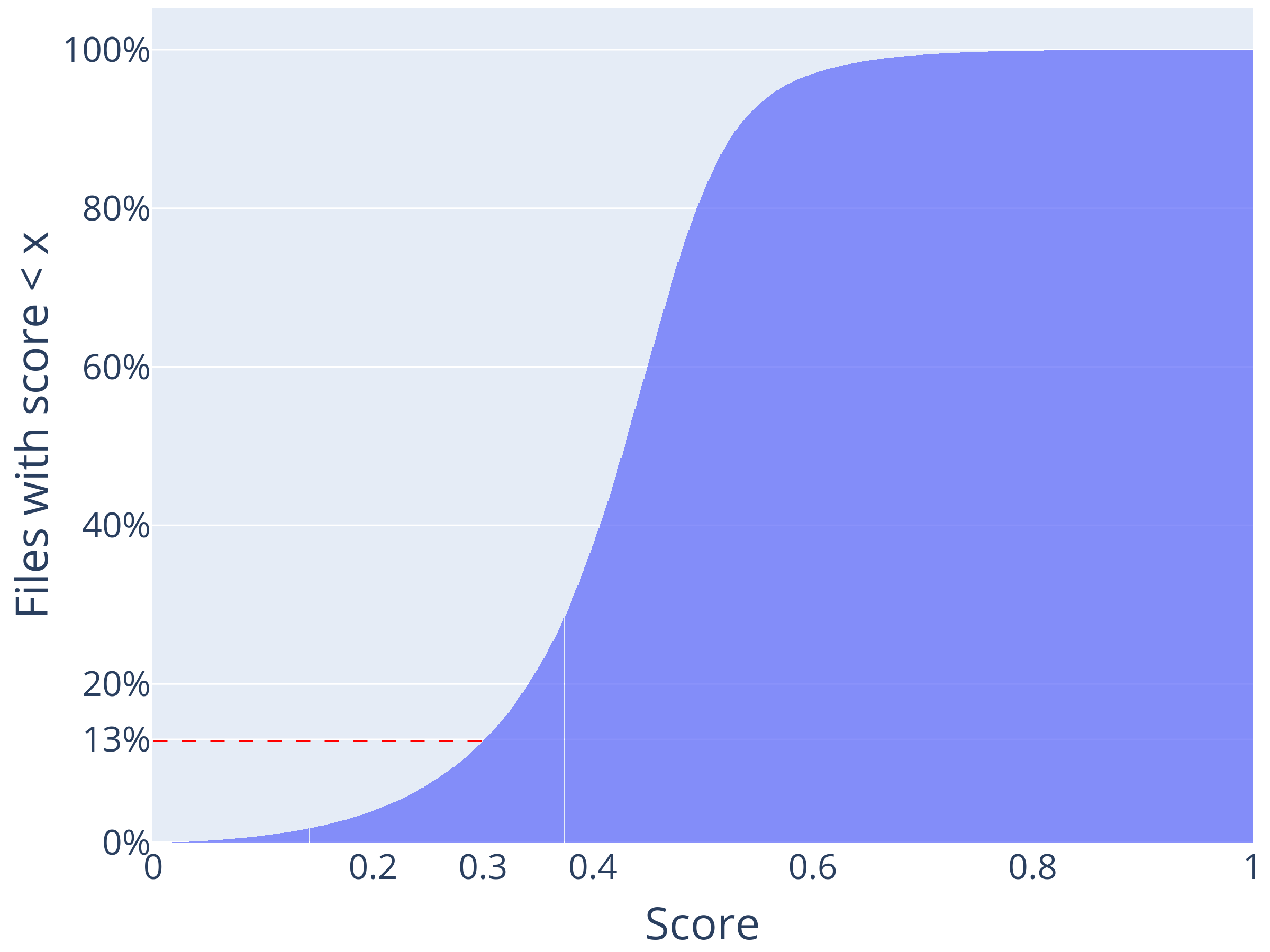
We provide two versions of the dataset: raw and pre-processed.